Encapsulated Data in Automation Programming
One problem we face when developing an automation solution is managing and organizing the vast amounts data that are needed. This applies to numerous scenarios, whether it is developing a tracking system, controlling conveyors, or discrete machine control. Not only is the organization of the data important to the control system directly, graphics development is equally concerned.
When presented with the challenge of developing a new automation solution, one of the first, and easiest traps to fall into is jumping into code development too quickly. This usually happens right after the I/O list is roughed in. The general mentality is that the code has to be finished ASAP to allow the graphics folks to get working on the screens and animation, but let???s think about an alternative approach.
Modern control processors offer significant improvement over the typical PLCs of the past. These improvements are, in part, the result of advances in computer theory, specifically object oriented programming (OOP). One of the concepts in OOP is called encapsulation. This idea stresses putting all of the characteristics of something together into one container or object. The idea being, if you want to know about a something, you only have to go to one place to find it. Conversely, all somethings have the same characteristics available. (This is grossly over-simplified, but it gets the point across).
Today???s control processors provide the ability of achieving encapsulated and highly organized data through the use of user defined data-types (UDT). Most manufacturers not only provide UDTs for developers, but employ the concept liberally themselves; for an example, look at the definition of a timer or counter type. These data types are made up of a collection of even more basic data types ??? Booleans, integers, etc.
The process begins, for me, with a spreadsheet layout that I’ve refined over time, some basic symbology, and the rough I/O list. Diagram 1 is an example of the basic symbols that I use for the data. The symbols are broken down into two basic areas: HMI and Proc(ess). The HMI symbols will be of great importance to the graphics developer, while the Proc symbols detail how the data moves through the program.

Diagram 1: Basic symbolism
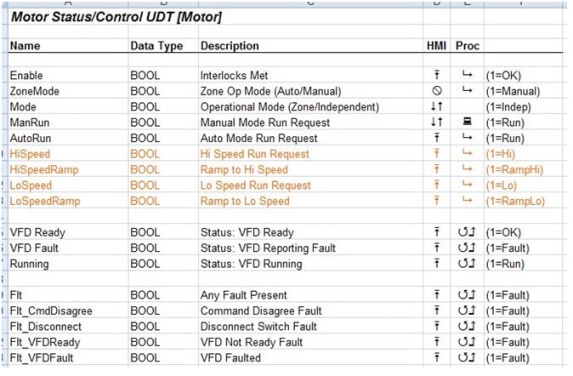
At this point, the challenge is to develop UDT definitions that will contain all of the necessary data elements for all like things. As an example, let???s consider a conveyor line and the motors that it uses. There are numerous characteristics of each motor: is it enabled, are the interlocks met, has the motor faulted, is it in Auto mode, and so on. Diagram 2 is a sample of a part of an individual motor definition that was developed.

Diagram 2: Sample motor UDT
The name, type, and description columns refer to the individual characteristic and what it means. The right-hand (un-named) column helps to clarify the meaning of the actual value. Of big help to the HMI folks is what the actual point means to them ??? the data can be read, written, either, don’t touch, etc. The Proc field indicates where it???s from, how its flows and where / how it???s generated. There are no real requirements here, just information that adds clarity to the material in total.
Not only can the UDT contain basic data types, but it can be made up of other UDTs, as evidenced in diagram 3.
Diagram 3: Contained UDT???s as elements
The upper portion is still part of the motor definition and it contains further UDTs of additional encapsulated data.
After mapping out all of the requirements of the system or process, we have generated several things:
??? A significant amount of documented data in the controller
??? Documentation to pass along to the graphics developer, and
??? A reasonably well thought-out approach on how to write the actual code!
Once all of the UDTs have been input and controller tags created, development is well on its way. Obviously, writing the code is not trivial, but writing routines that deal with all or part of the data is further simplified by allowing those routines to work with the entire block of data; ALL of it, not just a few variables. Continuing on from this point, routines need to ensure that:
??? Data is moved into registers (example: field inputs)
??? Functional control is executed (example: interlocks are developed), and
??? Data is moved out of registers (example: field outputs)
In general, when following this methodology, the code itself is more modular in nature and therefore much easier to maintain. It also lends itself to more thoroughly documented code, which is always a plus.
This is one approach to programming and it is not necessarily the only way to solve the problem. However, I believe that it is one more option that can be added to an automation developer???s bag of tricks.